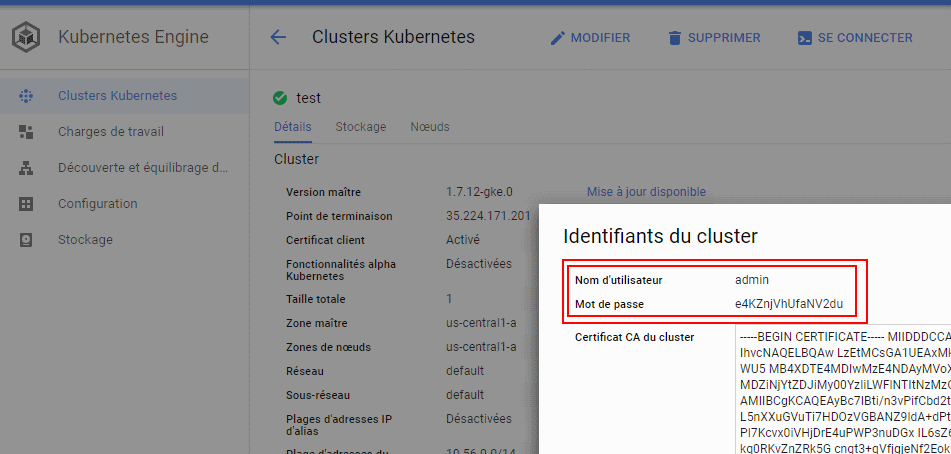
When a Kube cluster is created on Google Kube Engine you have access to a user/password combination that you could use to authenticate with Kube API.
This method of authentication is part of the official documentation of kubernetes:
“Kubernetes uses client certificates, bearer tokens, an authenticating proxy, or HTTP basic auth to authenticate….” From https://kubernetes.io/docs/admin/authentication/
I wanted to try this authentication method with the official kubernetes python client: https://github.com/kubernetes-client/python
Remote cluster
The first issue I had was to specify a remote cluster since all the example of the API used a .kubeconfig and suppose that the kube client is on the server (and usable).
After some digging I find the proper options and made a PR to add such example in the API doc: https://github.com/kubernetes-client/python/pull/446
Bearer token auth
The second issue was due to the BASIC authentication. There is already a ticket open about it (just few days before): https://github.com/kubernetes-client/python/issues/430
There was no solution in it so I decided to dig in 😉
After reading the code of the API I was only able to find the “bearer token” authentication method. There was nothing about the BASIC auth. I decided first to try the “bearer token” method to ensure the rest of my code was working fine. I submit an example of it on the ticket with the code below:
from kubernetes import client, config
#see https://kubernetes.io/docs/tasks/administer-cluster/access-cluster-api/#accessing-the-cluster-api to know how to get the token
#The command look like kubectl get secrets | grep default | cut -f1 -d ' ') | grep -E '^token' | cut -f2 -d':' | tr -d '\t' but better check the official doc link
aToken="eyJhXXXXXXXX82IKq0rod1dA"
# Configs can be set in Configuration class directly or using helper utility
configuration = client.Configuration()
configuration.host="https://XXX.XXX.XXX.XXX:443"
configuration.verify_ssl=False
configuration.debug = True
#Maybe there is a way to use these options instead of token since they are provided in Google cloud UI
#configuration.username = "admin"
#configuration.password = "XXXXXXXXXXX"
configuration.api_key={"authorization":"Bearer "+ aToken}
client.Configuration.set_default(configuration)
v1 = client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
print("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
It allows me to validate the “remote” cluster communication and also the token authentication nevertheless it is not my final goal.
Basic auth
Python kube API hack
I spend some time digging in the code and did not find any code related to the BASIC auth. I check in the code and the method “get_basic_auth_token” in configuration.py is never call anywhere (and it is the only one dealing with username/password field).
Then I try to “hack” a little the python code by modifying the class configuration and change its auth_setting with that
def auth_settings(self):
"""
Gets Auth Settings dict for api client.
:return: The Auth Settings information dict.
"""
return {
'BearerToken':
{
'type': 'api_key',
'in': 'header',
'key': 'authorization',
'value': self.get_api_key_with_prefix('authorization')
},
'http_basic_test':
{
'type': 'basic',
'in': 'header',
'key': 'Authorization',
'value': self.get_basic_auth_token()
},
}
I just added the “http_basic_test” here. Then you can take any functional class like “”core_v1_api and modify the method you plan to use (list_pod_for_all_namespaces_with_http_info in my case) and modify the auth part of the code. Replace:
auth_settings = ['BearerToken']
with
auth_settings = ['http_basic_test']
and then you can use username/password to authenticate (I verified and it works)
You should have valid response and even see the basic auth info if you activate debug log (like it is done in my previous answer):
send: b'GET /version/ HTTP/1.1\r\nHost: XXX.XXX.XXX.XXX\r\nAccept-Encoding: identity\r\nAccept: application/json\r\n
Content-Type: application/json\r\nUser-Agent: Swagger-Codegen/4.0.0/python\r\nAuthorization: Basic YWRXXXXXXXXXXXRA==\r\n\r\n'
This confirms that the basic auth can be used (as the kubernetes mentioned) but is not accessible from the python API.
Clean solution
The previous hack allowed me to be sure that I could authenticate with the cluster using the user//password nevertheless we cannot keep such dirty hack.
After some investigation I find out the Python kube client is generated by swagger. The generator code is located here: https://github.com/kubernetes-client/gen
This repo relies on the kubernetes swagger file located on the kubernetes repo:
https://raw.githubusercontent.com/kubernetes/kubernetes/master/api/openapi-spec/swagger.json
The URI of the swagger file is partialy hardcoded in the python file preprocess_spec.py
spec_url = 'https://raw.githubusercontent.com/kubernetes/kubernetes/' \ '%s/api/openapi-spec/swagger.json' % sys.argv[2]
Then I check the swagger file with a specific look on the security part:
"securityDefinitions": {
"BearerToken": {
"description": "Bearer Token authentication",
"type": "apiKey",
"name": "authorization",
"in": "header"
}
},
"security": [
{
"BearerToken": []
}
]
So there is indeed ne reference to any BASIC authentication process here. This is strange since the official doc mention it and since we just validated it works fine.
Let’s try to generate again the python kube library after adding the BASIC auth in the swagger file 😉
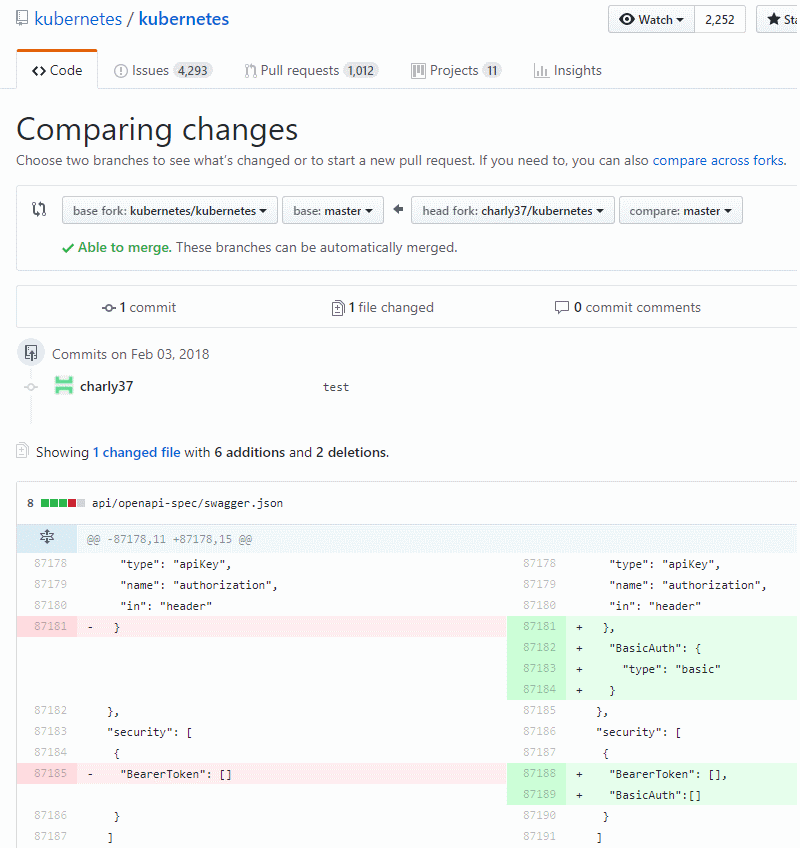
So I fork the kubernetes repo and modify the swagger file:
"securityDefinitions": {
"BearerToken": {
"description": "Bearer Token authentication",
"type": "apiKey",
"name": "authorization",
"in": "header"
},
"BasicAuth": {
"type": "basic"
}
},
"security": [
{
"BearerToken": [],
"BasicAuth":[]
}
]
(you can see the diff here: https://github.com/kubernetes/kubernetes/compare/master…charly37:master)
Then we need to patch the generator to use my fork swager file. I just change the URI in preprocess_spec.py with:
spec_url = 'https://raw.githubusercontent.com/charly37/kubernetes/' \ '%s/api/openapi-spec/swagger.json' % sys.argv[2]
And then generate again the python library with:
./python.sh test test.sh
This comes from the README of the generator here: https://github.com/kubernetes-client/gen and the test.sh file content is:
[charles@kube openapi]$ cat test.sh export KUBERNETES_BRANCH=master export CLIENT_VERSION=1.0.0b1 export PACKAGE_NAME=kubernetes
This will start a docker container and build the python library in the output directory which is ./test in our case:
… [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 11.396 s [INFO] Finished at: 2018-02-03T22:18:51Z [INFO] Final Memory: 26M/692M [INFO] ------------------------------------------------------------------------ ---Done. ---Done. --- Patching generated code... ---Done.
To be sure that the new security setup was taken into account we check the new python code and more specifically the configuration.py file with
vi test/kubernetes/configuration.py
leading to see:
# Authentication Settings
# dict to store API key(s)
self.api_key = {}
# dict to store API prefix (e.g. Bearer)
self.api_key_prefix = {}
# Username for HTTP basic authentication
self.username = ""
# Password for HTTP basic authentication
self.password = ""
We now have parameters related to the BASIC authentication. Seems very good 😉
We install this generated library with:
[root@kube test]# python setup.py install
The last piece of the test is to replace the bearer token in our test script with these new parameters:
aUser = "admin"
aPassword = "e4KZnjVhUfaNV2du"
...
#configuration.api_key = {"authorization": "Bearer " + aToken}
configuration.username = aUser
configuration.password = aPassword
And run the script:
[root@kube ~]# python kubeConect.py
Listing pods with their IPs:
[root@kube ~]# python kubeConect.py Listing pods with their IPs: /usr/lib/python2.7/site-packages/urllib3-1.22-py2.7.egg/urllib3/connectionpool.py:858: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 10.56.0.8 kube-system event-exporter-v0.1.7-91598863-kkzgw 10.56.0.2 kube-system fluentd-gcp-v2.0.9-nc8th 10.56.0.10 kube-system heapster-v1.4.3-2870825772-h9z8j 10.56.0.7 kube-system kube-dns-3468831164-t5ggk 10.56.0.3 kube-system kube-dns-autoscaler-244676396-r5rnm 10.128.0.2 kube-system kube-proxy-gke-test-default-pool-477f49cb-fksp 10.56.0.4 kube-system kubernetes-dashboard-1265873680-kzdn2 10.56.0.6 kube-system l7-default-backend-3623108927-rkv9w
It works !! Now we know that if we update the swagger file we will be able to use the BASIC auth with the python kube client library. The last step is to talk with the rest of the community to find out why the BASIC auth is not supported on the client libs (all generated from the swagger file) even if it is activated on Kube and present in the official doc…