In addition to the Neural network solution I explain in the previous article I also tried other algorithms like Decision Tree and Random Forest.
Algorithm
Accuracy
Neural Network
96.63%
Random Forest
96.96%
Decision Tree
96.76%
Refined Decision Tree
97.64%
Refine decision tree?
One of the conclusions of all my tests with ML from the previous article is the complexity to choose the parameters needed by each model. Hopefully a friend suggests me a solution “GridSearchCV” which allows to test various parameter for an algorithm and find the best ones.
The algorithm I called “refined decision tree” is a decision tree based on the best parameters “GridSearchCv” found.
#Now let s try to refine the Decision tree by trying several parameters
aGridSearchParams = {'max_features': [None, 'sqrt'],'max_depth' : [3, 5, 10, None],'min_samples_leaf': [1, 2, 3, 5, 10],'min_samples_split': [2, 4, 8, 16],'max_leaf_nodes': [10, 20, 50, 100, 500, 1000]} # instantiate the grid aGridSearchResult = GridSearchCV(DecisionTreeClassifier(), aGridSearchParams, cv=5, ) # fit the grid with data aGridSearchResult.fit(atrainDataX, atrainDataY)
#let s see how good it is
aDecisionTreeRefinedPrediction = aGridSearchResult.best_estimator_.predict(atestDataX)
I used the Neural Network and the “refined decision tree” in the application to compare them and notice that the neural network was slightly better. For example
root - INFO - Checking if group should be refresh by calling ML with: [1, 47, 10, 0] root - INFO - We found 1 new message and the ML probability were NN: [[0.11245716]], DT[[1. 0.]]
When trying to predict if a group with characteristics:
Latest refresh done 1 days ago
47 users in the chat room
Latest message in the group was posted 10 days ago
0 messages posted in the last week in the chatroom
The Neural network predict a probability of 11% of new messages while the “refined decision tree” predicted 0% chance. We found new messages in the room leading for a false positive for the “refined decision tree” which we want to avoid at all cast. I just stick to the neural network for now.
Optimizer change on NN
When training the Neural Network, I sometime end up with very poor results. The model seems stuck and always predict the same output:
NN atestDataYPredictedKeras: [0.05339569 0.05339569 0.05339569 ... 0.05339573 0.05339573 0.05339573]
Even if the test case is composed of around 1500 lines.
NN len(atestDataYPredictedKeras): 1484
This happen from time to time and it usually get away if I retrain the model nevertheless it makes the final results very bad if I did not check the training results every time.
Luckily, I’m not the only one in this case ? according to this github ticket.
I tried some of the suggestions proposed on the page and one that seems to be the best was to modified the optimizer from SGD to Adam. After some reading, I decided to go with it since Adam seems to be a good choice according to the ML community. This youtube video explain some of the possible optimizer algorithm and also suggest adam as default choice. Nevertheless, like all topic/parameters in ML you can always find arguments about the opposite like this article:
“We construct an illustrative binary classification problem where the data is linearly separable, GD and SGD achieve zero test error, and AdaGrad, Adam, and RMSProp attain test errors arbitrarily close to half.”
I will still stick to Adam for now since it fixes my original issue with the same accuracy and smaller loss:
I have a bot part of several (around 250) chat groups (think discord rooms). The bots connect everyday with an undocumented API to get for each room the new messages. Since the API is not fully documented I’m not sure it was designed to be used for robotic access. I thus decided to try to predict if a room will have new messages and reduce the number of calls. That was a fun opportunity to try to do ML.
Features
First, I need to find some “features” that will be used to predict the output (there are new messages to get or not). I tried several versions and the actual features are
number of days since the last refresh
integer to indicate how many days have passed since the latest time we call the API to refresh messages. For example, if we are the 7 JAN when we are doing a refresh and the latest was done 1 JAN this field value will be 7 – 1 = 6 days.
number of users in the chat group
integer which indicates the number of users in the group for which we call the API to refresh messages.
number of days since the latest message was posted in this group
integer to indicate the number of days has passed since the latest message was posted in the group (compared to the date of the refresh) For example, if we last refresh for this chat room was done the 7 JAN and we old message in the chat group at this time was 1 JAN the value of this field will be 7 – 1 = 6 days.
number of messages in the latest 7 days
integer to indicate the number of messages in the chat room in the latest 7 days
I logged the values for each of these features when calling the API for few days as well as the result of the call: were there new messages in the group or not. I write the results in 2 files which will be used to train and test the MN.
Examples
0;1;8;555;0
One day we call the refresh API on a chat room to get new messages and did not get anything. At this time the number of days since the latest refresh was 1 (we checked the day before) and the number of users in the chat room was 8. We also know that the most recent message is 555 days old and there were 0 message in the latest week.
1;1;10;4;2
One day we call the refresh API on a chat room to get new messages and found some. At this time the number of days since the latest refresh was 1 (we checked the day before) and the number of users in the chat room was 10. We also know that the most recent message is 4 days old and there were 2 messages in the latest week.
This is still a work in progress and I’m getting feedback from other people I’m working with so I share the file and feature explanation on a dedicated google drive folder. You should rather check it to get more info and the latest feature used.
ML
I decided to use Keras since it has good review. It works on top of various ML engines and allow fast experimentation “Keras is a high-level API capable of running on top of TensorFlow, CNTK, Theano, or MXNet (or as tf.contrib within TensorFlow). Since its initial release in March 2015, it has gained favor for its ease of use and syntactic simplicity, facilitating fast development. It’s supported by Google.”
Data
I split the data in 2 files with the 80/20% proportion. The data are csv files formatted as explained in the previous section. Latest data and info are available on the following folder.
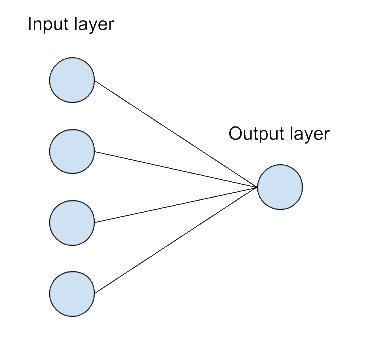
I decided to use a Neural network with 4 input (since we have 4 features) in the input layer connected to a single neuron as output layer.
It’s the most basic design I could imagine. I saw some article where people suggest to add a hidden layer but I was not sure how to decide. The “design” of the neural network was the first challenge I face. I will do a dedicated post on this point later.
There are several other parameters like the activation functions for each layer. I choose “relu” for the first layer and “sigmoid” for the output after some quick reading but I’m clearly not sure it’s the best choice. There are so many possibilities and no clear real explanations on which to choose.
One of the reason I choose Keras was the simplicity to get results “developed with a focus on enabling fast experimentation” (https://keras.io/). Training is a simple call to the “fit” function
The model is train with the training data and I choose a random value of 100 epochs which seems to be a good value from what I read from other article (especially for the small amount of data I have).
When call the python code will output the results of each epoch
At the end of the training the model has a 95% rate success in its prediction. The next step is to evaluate the model with unknown new cases from the testing set.
Testing
Once the model has been trained with the training data (as a reminder I split my data 80% train / 20% test) we can evaluate how good it predicts with the test data. This is done with the evaluate method of Keras:
NN algorithm results: [0.14495629791642295, 0.9595687389373779] for folowwing metrics : ['loss', 'accuracy']
We achieve good results too on the testing set with 96% accuracy.
Threshold
The neural network output a percentage as prediction:
root - INFO - Checking if group should be refresh by calling ML with: [4, 123, 560, 0] root - INFO - We found 0 new message and the ML probability were NN: [0.01339133] … root - INFO - Checking if group should be refresh by calling ML with: [4, 16, 0, 9] root - INFO - We found 1 new message and the ML probability were NN: [0.75237719]
Since I want to be sure to never miss a possible message I decided to take a very low threshold at 2% which means we are probably calling some time and not find anything. I will review it after the ML results are compare to the reality for a few days. Nevertheless, if you never heard the term “confusion matrix” you may want to have a look at it now since we will use it later to review our threshold. There are some explanations about it here.
Results
I saved the model with
aKerasNnModel.save("model.h5")
And then used it in my real-life application. I logged the prediction of the model but still called the API to get the new messages from the chat rooms so I can log a confusion matrix.
As explain previously I choose a very low threshold to ensure to avoid any false negative even if it means having few false positive because I do not want to miss any messages. At the end we reduce our number of calls to the API from 273 to only 35 and did not lost any messages. The threshold seems good enough for now.
Conclusion
I’m glad I had a project where I could have some fun discovering ML with a real-life application. As a non-expert and first-time user of Neural network I find it quite complicated and easy at the same time. It s easy since I manage to get good results very quickly without too much efforts but… It’s hard because there are lot of unknow variables like the network shape or the different function (activation, loss, optimizer). For most of these parameters I did not find any good documentation on which one to choose (and the articles sometimes contradicts each other).
This article is just a short sum up of my work on this project since I did not discuss of the other machine learning algorithms I tried (and compare to NN): Decision tree and Random Forest. I also did not discuss an issue I had when training the network and get stuck with a model which always answer the same prediction. I plan to do a follow up to develop these issues later.